SuperCLUE-RAG
SuperCLUE-RAG: 中文原生检索增强生成测评基准
随着人工智能技术的快速发展,大型语言模型在处理复杂、开放领域的问题时,常常面临知识获取和更新的挑战。它们所依赖的训练数据可能有限且过时, 无法覆盖所有领域的知识,导致生成的内容缺乏准确性和时效性。 同时,在现实世界的应用场景中,用户期望获得最新、最准确的信息。
正是在这样的背景下,RAG(检索增强生成)技术结合了检索和生成两种方法的优势应运而生。RAG通过利用外部知识库中的信息,为语言模型提供了更全面、 准确且最新的背景知识,使其在生成回答或文本时能够参考更多、更可靠的信息。 这不仅提高了模型的准确性,也使其更加实用和可信。同时,RAG方法还避免了昂贵的模型微调,允许模型在运行时动态地访问和更新知识库,从而提高了效率。
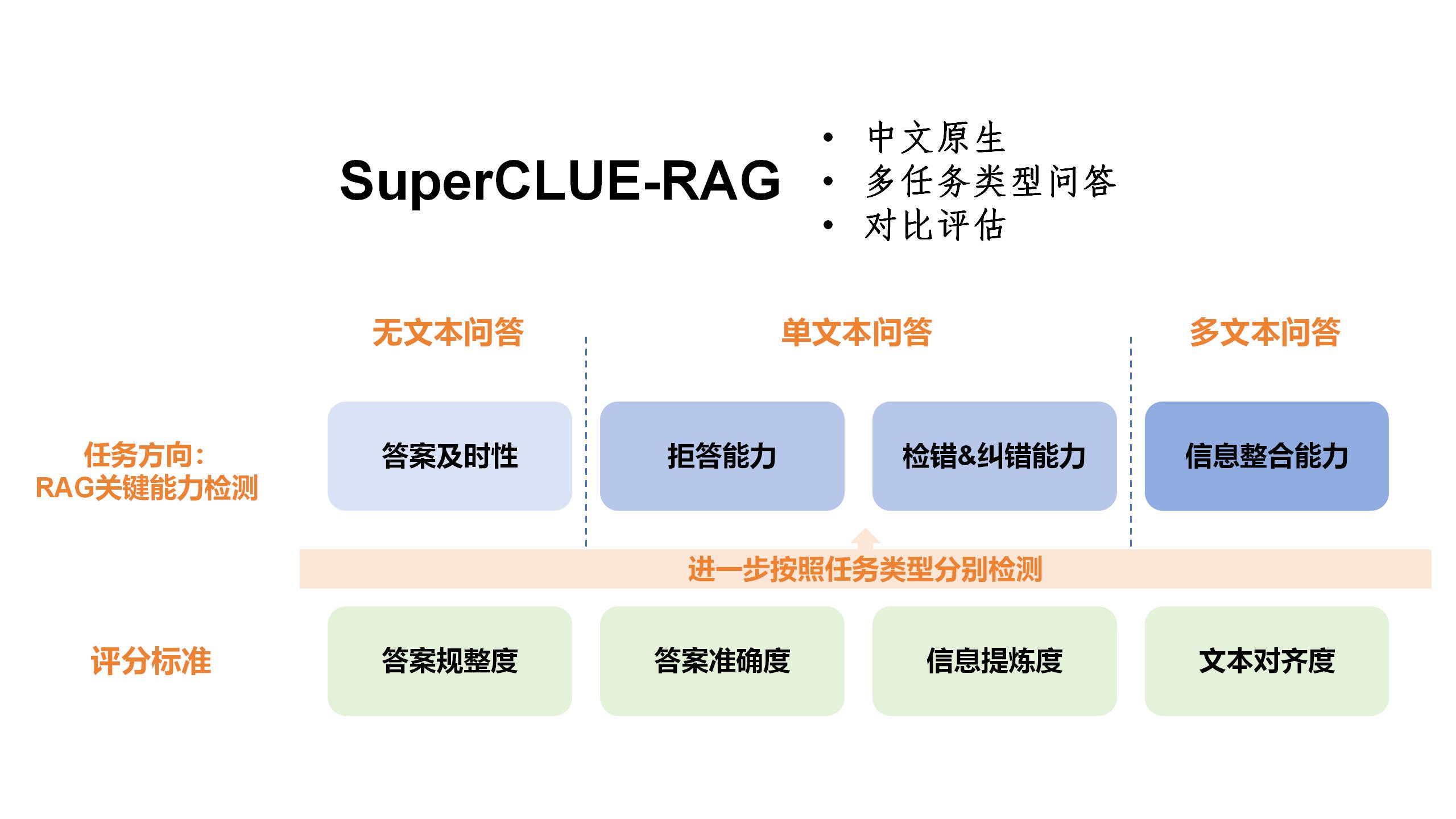
为了对国内外大语言模型的RAG技术发展水平进行评估并据此提出改进建议,我们发布了SuperCLUE-RAG(SC-RAG)中文原生检索增强测评基准, 采用了不同于以往SuperCLUE评估方法的对比式测评模型, 依据不同的任务类型,全方位、多角度地对RAG技术水平进行测评。
立足于为通用人工智能时代提供中文世界基础设施,文字输入或prompt提示词都是中文原生的;并充分考虑国内RAG技术的发展状况与应用场景, 从国内RAG应用实际问题出发,致力于打造适合中国语义环境的RAG技术测评指标。
基于RAG技术应用的主要场景,该测评指标设置了三种主要问答模式:
不同于以往的测评体系,SuperCLUE-RAG还采用了对比式问答模式。除无文档问答类任务以外,针对同一问题进行先后两次提问,第一次不提供任何外部文档信息, 第二次人为提供预设文档,对比两次答案的差异,并依据对比下暴漏的具体问题对系统RAG应用能力进行评估。
参考SuperCLUE一贯的细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息。
中文prompt构建流程:1.参考现有prompt--->2.中文prompt撰写--->3.测试--->4.修改并确定中文prompt
参考国际标准和当前已有工作,针对每一个维度构建专用的测评集。
评估流程:1.获得<中文prompt>-->2.依据评估标准-->3.使用评分规则-->4.进行细粒度打分
结合超级模型,在定义的指标体系里明确每一个维度的评估标准。结合评估流程、评估标准、评分规则,将文本输入送入超级模型进行评估,并获得每一个维度的评估结果。
进行评估与人类一致性分析,并报告一致性表现。
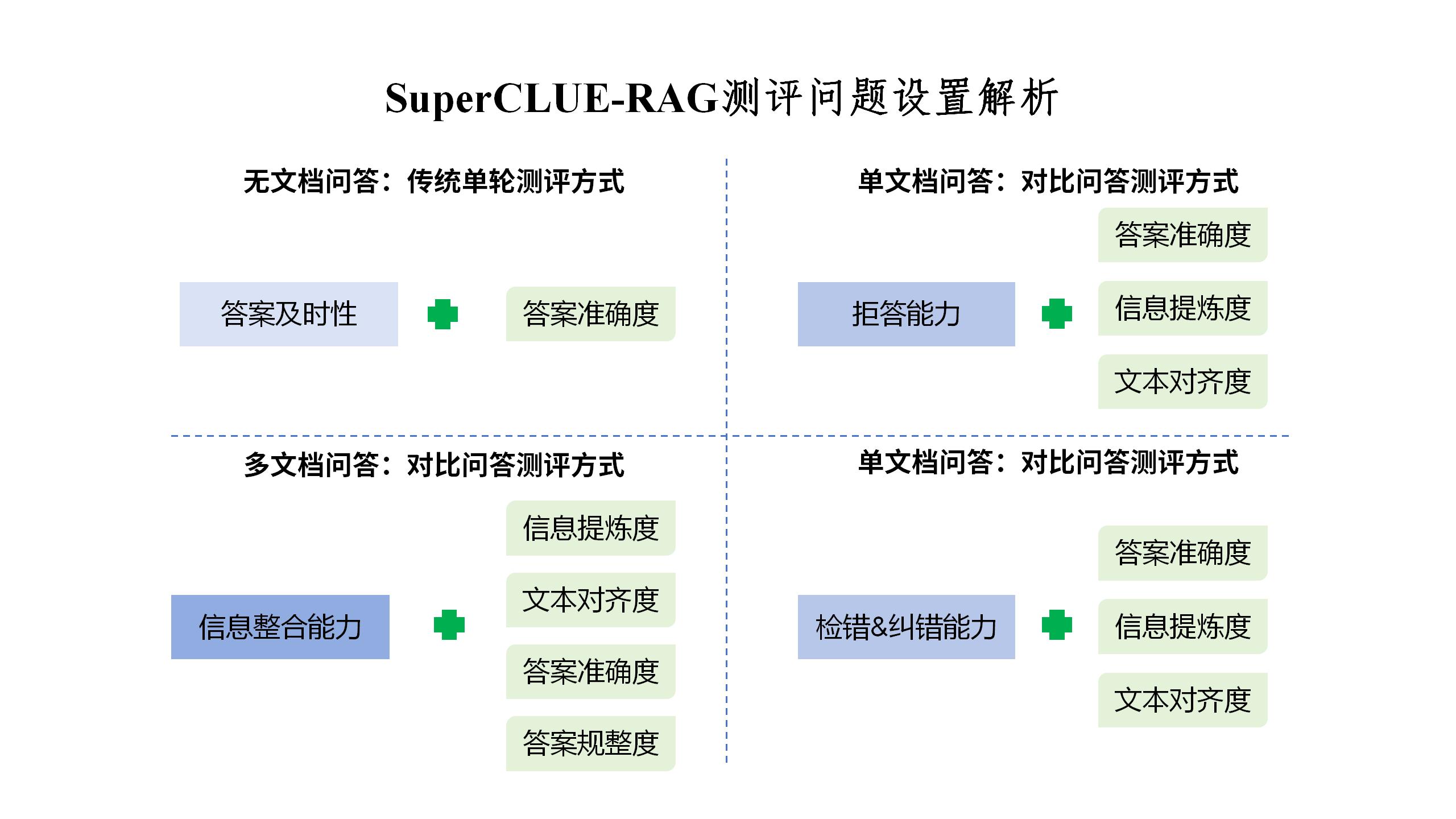
测评体系分为评分标准与任务方向。
考察生成答案是否按照需求标准回答,强调要求文本具有清晰的因果关系、逻辑关系、时间顺序等,同时具有总结、分析的过程体现。
例如:在“整理美国大选2024年以来各位候选人的动态数据并分析谁的当选概率更大”问题中,应该分别描述各位候选人的情况,且需要理清时间线和变化趋势, 同时在分析谁更有可能当选的问题时,应该以描述内容为依据进行分析,而不是独立生成答案。
考察生成答案的内容是否与提问的需求高度一致,确保答案直接且专注地解决问题的核心点。该指标不仅衡量答案的事实准确性, 还包括其对问题的直接响应程度,并剔除与问题核心无关的信息,确保信息的紧凑性和目标导向性,答案文本中冗余信息的比例较低。
例如:“请告诉我2023年诺贝尔文学奖获得者是谁”,应当准确回答2023年的诺贝尔文学奖获得者名单,而不包括其他年份的获奖者。
考察在描述性需求下,模型能够做到在相似文档或噪声文档中精准提取出补充信息,在全面、综合提炼文档信息的基础上, 要求生成文本应当能够做到完善回答问题涉及的各个方面。
例如:给定一系列企业的财报业绩文档如苹果、谷歌、华为、小米等,针对“请告诉我华为最新季度的收入增长以及各个分支盈亏的具体信息并反馈在文档
中所体现的关键业务进展。”等问题,生成文本应当能够实现详细的反馈和整理。
考察生成文本与提供文档内容之间的关联性,应当能够呈现高相关度,内容紧密结合。
例如:结合以上文档内容,梳理今年两会的最新进展,要求完全按照文档内容进行整理、归纳,则生成文本中的各项方针政策应当围绕今年两会的详细情况而展开叙述。
在最新的时间标准下准确回答问题,重点考察系统对最新信息的捕获能力。(该部分不提供文档,考察系统对于网页信息的捕获能力。)
例如:假设今天是2024年3月6日,请系统回答2024年3月6日最新的A股指数。
对于敏感问题或文档中不存在相关信息的问题应拒绝回答而非给出模糊答案。(单文档问题)
例如:给定一系列企业的财报业绩文档如苹果、谷歌、华为、小米等,针对“请给出美国大选中拜登为什么退出竞选的理由”,应当以信息不完备而拒绝回答。
对于问题中有未更新的错误信息的,应当指出错误信息,修改后再返回。(单文档问题)
例如:针对“目前已知最大的星系是距离银河系的IC 1101,直径约为400万光年,对吗?”,应当根据最新的文档信息生成“不对,
目前已知的最大星系是距离银河系约30亿光年的阿尔库俄纽斯星系,直径约为1630万光年”。
根据提供的多条文档内容,能够具有多文档的检索记忆能力,并且根据检索的内容进行多步推理与整合,最终给出精确、完整的答案。(多文档问题)
例如:根据提供的多段文档信息,整理归纳中亚五国在过去两个月内的动态与重大事件发展趋势。
基于SuperCLUE-RAG测评体系的特殊性(对比式问答模式),全部题目基于RAG关键技术检测的四个任务方向设置问题,分为无文档问答、单文档问答、多文档问答三种形式, 灵活采用评分标准进行赋分,进而得出多维评估结果。
报名:3月11日----3月22日
参测模型确认:3月22日
测评执行:3月15日--3月下旬
测评报告发布:3月下旬
邮件标题:SuperCLUE-RAG检索增强测评申请,发送到contact@superclue.ai
请使用单位邮箱,邮件内容包括:单位信息、文生视频大模型简介、联系人和所属部门、联系方式


SuperCLUE中文大模型排行榜(2023年7月)
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| - | GPT-4 | OpenAI | 70.89 | 70.04 | 72.67 | 69.96 | 专有服务 |
| 🏅 | 文心一言(v2.2.0) | 百度 | 62.00 | 61.11 | 71.38 | 53.50 | 专有服务 |
| - | Claude-2 | Authropic | 60.94 | 62.01 | 61.18 | 59.63 | 专有服务 |
| - | gpt-3.5-turbo | OpenAI | 59.79 | 64.40 | 63.19 | 51.78 | 专有服务 |
| 🥈 | ChatGLM-130B | 清华大学&智谱AI | 59.35 | 53.78 | 71.39 | 52.89 | 专有服务 |
| 🥉 | 讯飞星火(v1.5) | 科大讯飞 | 58.02 | 63.32 | 65.72 | 45.03 | 专有服务 |
| - | Claude-instant-v1 | Authropic | 56.31 | 58.85 | 55.91 | 54.16 | 专有服务 |
| 4 | 360智脑(4.0) | 360 | 55.04 | 56.68 | 62.54 | 45.88 | 专有服务 |
| 5 | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 6 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 7 | MiniMax-abab5.5 | MiniMax | 53.06 | 53.61 | 62.79 | 42.77 | 专有服务 |
| 8 | 通义千问(v1.0.3) | 阿里巴巴 | 51.52 | 52.84 | 61.73 | 39.98 | 专有服务 |
| 9 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 10 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 11 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 12 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 13 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 14 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 15 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 16 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |
2023年7月SuperCLUE基础能力榜单
| 排名 | 模型 | 平均分 | 语义理解 | 闲聊 | 对话 | 角色扮演 | 知识与百科 | 生成与创作 | 逻辑与推理 | 代码 | 计算 | 安全 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 85.03 | 90.17 | 71.53 | 77.99 | 82.19 | 97.44 | 68.79 | 90.55 | 90.45 | 94.97 | 86.22 |
| - | gpt-4 | 70.04 | 82.91 | 46.77 | 66.39 | 63.46 | 92.65 | 66.67 | 60.33 | 85.45 | 61.48 | 73.02 |
| - | gpt-3.5-turbo | 64.40 | 87.18 | 45.16 | 65.57 | 60.58 | 85.29 | 72.36 | 42.98 | 72.73 | 38.52 | 72.22 |
| 🏅️ | 讯飞星火(v1.5) | 63.32 | 78.26 | 45.90 | 59.84 | 55.88 | 73.48 | 54.92 | 54.70 | 60.00 | 76.86 | 71.54 |
| - | Claude-2 | 62.01 | 83.49 | 49.59 | 57.14 | 52.88 | 78.68 | 68.07 | 53.72 | 66.06 | 44.26 | 65.60 |
| 🥈 | 文心一言(v2.2.0) | 61.11 | 81.90 | 46.34 | 56.67 | 59.80 | 86.76 | 47.73 | 36.52 | 65.79 | 52.63 | 70.63 |
| - | Claude-instant-v1 | 58.85 | 76.52 | 50.00 | 58.20 | 55.77 | 77.04 | 61.48 | 40.00 | 66.97 | 33.61 | 67.77 |
| 🥉 | 360智脑(4.0) | 56.68 | 76.92 | 52.46 | 58.33 | 54.08 | 76.80 | 61.54 | 37.29 | 53.64 | 29.57 | 67.92 |
| 4 | ChatGLM2-6B | 55.60 | 74.36 | 44.35 | 55.74 | 56.73 | 76.47 | 51.22 | 40.50 | 41.82 | 45.08 | 66.67 |
| 5 | internlm-chat-7b | 54.85 | 80.34 | 48.39 | 55.74 | 55.77 | 77.94 | 36.59 | 37.19 | 51.82 | 34.43 | 68.25 |
| 6 | ChatGLM-130B | 53.78 | 70.94 | 45.97 | 56.56 | 61.54 | 75.74 | 55.28 | 29.75 | 45.45 | 31.15 | 63.49 |
| 7 | MiniMax-abab5.5 | 53.61 | 79.49 | 45.97 | 59.84 | 60.58 | 85.29 | 47.97 | 29.75 | 30.00 | 31.97 | 61.11 |
| 8 | 通义千问 | 52.84 | 74.77 | 45.97 | 57.98 | 53.00 | 76.69 | 38.89 | 33.06 | 46.67 | 39.67 | 60.40 |
| 9 | Baichuan-13B-Chat | 50.46 | 64.10 | 41.94 | 50.00 | 52.88 | 75.00 | 57.72 | 27.27 | 40.91 | 31.15 | 60.32 |
| 10 | BELLE-13B | 48.71 | 68.38 | 46.77 | 51.64 | 53.85 | 64.71 | 25.20 | 32.23 | 48.18 | 31.97 | 63.49 |
| 11 | IDEA-姜子牙-13B-v1.1 | 47.55 | 70.09 | 49.19 | 48.36 | 48.08 | 58.82 | 32.52 | 34.71 | 21.82 | 45.08 | 63.49 |
| 12 | Phoenix-7B | 45.39 | 66.67 | 41.94 | 43.44 | 43.27 | 55.15 | 44.72 | 31.41 | 36.36 | 33.61 | 55.56 |
| 13 | MOSS-16B | 37.01 | 54.70 | 39.52 | 40.16 | 45.19 | 35.29 | 34.96 | 24.79 | 32.73 | 27.05 | 37.30 |
| 14 | Llama-2-13B-chat | 35.85 | 52.14 | 41.94 | 40.98 | 32.69 | 33.82 | 38.21 | 28.93 | 23.64 | 27.05 | 38.10 |
| 15 | Vicuna-13B | 34.61 | 49.57 | 33.06 | 32.79 | 37.50 | 25.74 | 30.89 | 27.27 | 40.91 | 35.25 | 35.71 |
| 16 | RWKV-7B-World-CHNtuned | 30.71 | 31.62 | 20.16 | 22.13 | 26.92 | 27.21 | 23.58 | 22.31 | 36.36 | 60.66 | 36.51 |
2023年7月SuperCLUE中文特性榜单
| 排名 | 模型 | 平均分 | 字形和拼音 | 字义理解 | 句法分析 | 文学 | 诗词 | 成语 | 歇后语 | 方言 | 对联 | 古文 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 82.29 | 96.01 | 83.15 | 62.71 | 91.47 | 90.79 | 92.38 | 83.78 | 69.21 | 70.00 | 83.40 |
| - | gpt-4 | 72.67 | 62.83 | 68.07 | 85.48 | 88.08 | 75.68 | 95.12 | 70.15 | 38.40 | 71.52 | 67.31 |
| 🏅️ | ChatGLM-130B | 71.39 | 48.67 | 68.07 | 75.00 | 83.44 | 84.68 | 95.94 | 67.16 | 45.60 | 70.86 | 72.12 |
| 🥈 | 文心一言(v2.2.0) | 71.38 | 59.34 | 70.34 | 73.33 | 86.58 | 82.88 | 95.12 | 60.31 | 37.60 | 71.03 | 73.79 |
| 🥉 | 讯飞星火(v1.5) | 65.72 | 47.32 | 68.38 | 77.42 | 72.03 | 69.09 | 89.43 | 59.85 | 35.77 | 71.23 | 63.46 |
| 4 | ChatGLM2-6B | 63.59 | 45.13 | 60.50 | 66.13 | 78.81 | 63.06 | 89.43 | 64.18 | 33.60 | 64.24 | 66.35 |
| - | gpt-3.5-turbo | 63.19 | 46.02 | 69.75 | 75.81 | 75.50 | 57.66 | 89.43 | 55.97 | 36.00 | 57.62 | 66.35 |
| 5 | MiniMax-abab5.5 | 62.79 | 46.90 | 57.98 | 63.71 | 75.50 | 71.17 | 86.99 | 60.45 | 41.60 | 58.94 | 62.50 |
| 6 | 360智脑(4.0) | 62.54 | 45.45 | 63.83 | 63.53 | 71.43 | 70.73 | 97.06 | 60.47 | 38.46 | 64.96 | 73.21 |
| 7 | 通义千问 | 61.73 | 41.59 | 60.87 | 60.66 | 73.65 | 67.89 | 88.24 | 51.91 | 40.68 | 68.97 | 57.89 |
| 8 | internlm-chat-7b | 61.35 | 41.59 | 58.82 | 62.10 | 76.16 | 68.47 | 86.18 | 61.94 | 32.80 | 57.62 | 65.38 |
| - | Claude-2 | 61.18 | 48.67 | 70.94 | 70.16 | 67.55 | 54.05 | 83.74 | 58.21 | 36.00 | 60.67 | 59.62 |
| - | Claude-instant-v1 | 55.91 | 43.36 | 62.16 | 72.13 | 62.91 | 50.91 | 84.87 | 47.73 | 31.20 | 56.38 | 45.19 |
| 9 | Baichuan-13B-Chat | 55.38 | 45.13 | 58.82 | 50.81 | 73.51 | 70.27 | 75.61 | 47.01 | 33.60 | 44.37 | 54.81 |
| 10 | BELLE-13B | 52.99 | 42.48 | 55.46 | 67.74 | 56.29 | 46.85 | 78.05 | 38.06 | 33.60 | 59.60 | 49.04 |
| 11 | IDEA-姜子牙-13B-v1.1 | 48.61 | 28.32 | 54.62 | 51.61 | 56.29 | 51.35 | 63.41 | 42.54 | 36.00 | 48.34 | 51.92 |
| 12 | Phoenix-7B | 44.62 | 30.09 | 51.26 | 43.55 | 51.66 | 45.95 | 65.85 | 35.07 | 32.00 | 45.03 | 44.23 |
| 13 | MOSS-16 | 38.01 | 32.74 | 43.70 | 36.29 | 40.40 | 32.43 | 60.98 | 32.09 | 31.20 | 31.13 | 40.38 |
| 14 | Llama-2-13B-chat | 37.37 | 31.86 | 40.34 | 49.19 | 37.75 | 33.33 | 43.90 | 32.09 | 32.00 | 33.77 | 40.38 |
| 15 | Vicuna-13B | 33.71 | 21.24 | 34.45 | 45.16 | 29.14 | 22.52 | 33.33 | 36.57 | 22.40 | 49.67 | 38.46 |
| 16 | RWKV-7B-World-CHNtuned | 28.13 | 25.66 | 26.05 | 25.00 | 29.80 | 26.13 | 45.53 | 17.16 | 20.00 | 36.42 | 27.88 |
2023年7月SuperCLUE开源榜单
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| 🏅️ | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 🥈 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 🥉 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 4 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 5 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 6 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 7 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 8 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 9 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 10 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |