扫码关注

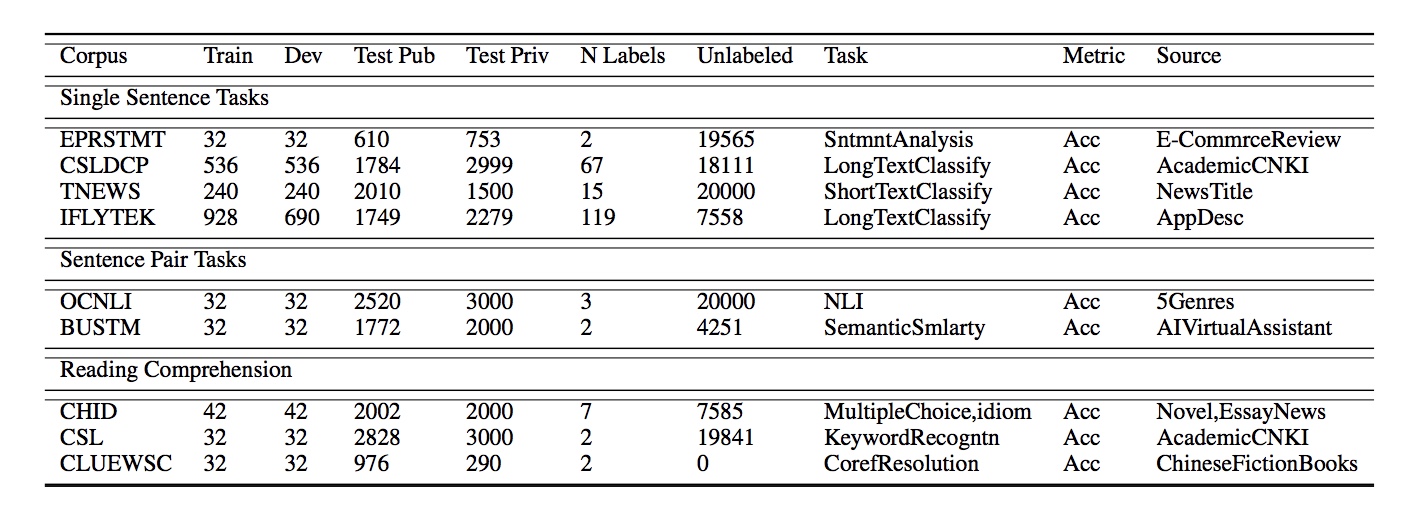
任务集列表
FewCLUE: A Chinese Few-shot Learning Evaluation Benchmark
DataCLUE: A Benchmark Suite for Data-centric NLP
ZeroCLUE: A Chinese Zero-shot Learning Evaluation Benchmark
KgCLUE: Large-scale Knowledge Graph based QA Benchmark
SimCLUE: Large-scale Semantic Matching Dataset
QBQTC: QQ Browser Query Title Corpus
Ant Financial Question Matching Corpus
Short Text Classification for News
Long Text classification
Chinese Multi-Genre NLI
The Winograd Schema Challenge,Chinese Version
Keyword Recognition
Reading Comprehension for Simplified Chinese
Chinese IDiom Dataset for Cloze Test
Multiple-Choice Chinese Machine Reading Comprehension
CLUE Fine-Grain NER
OCNLI: Original Chinese Natural Language Inference
下载地址:https://github.com/CLUEbenchmark/FewCLUE 文章:https://arxiv.org/abs/2107.07498
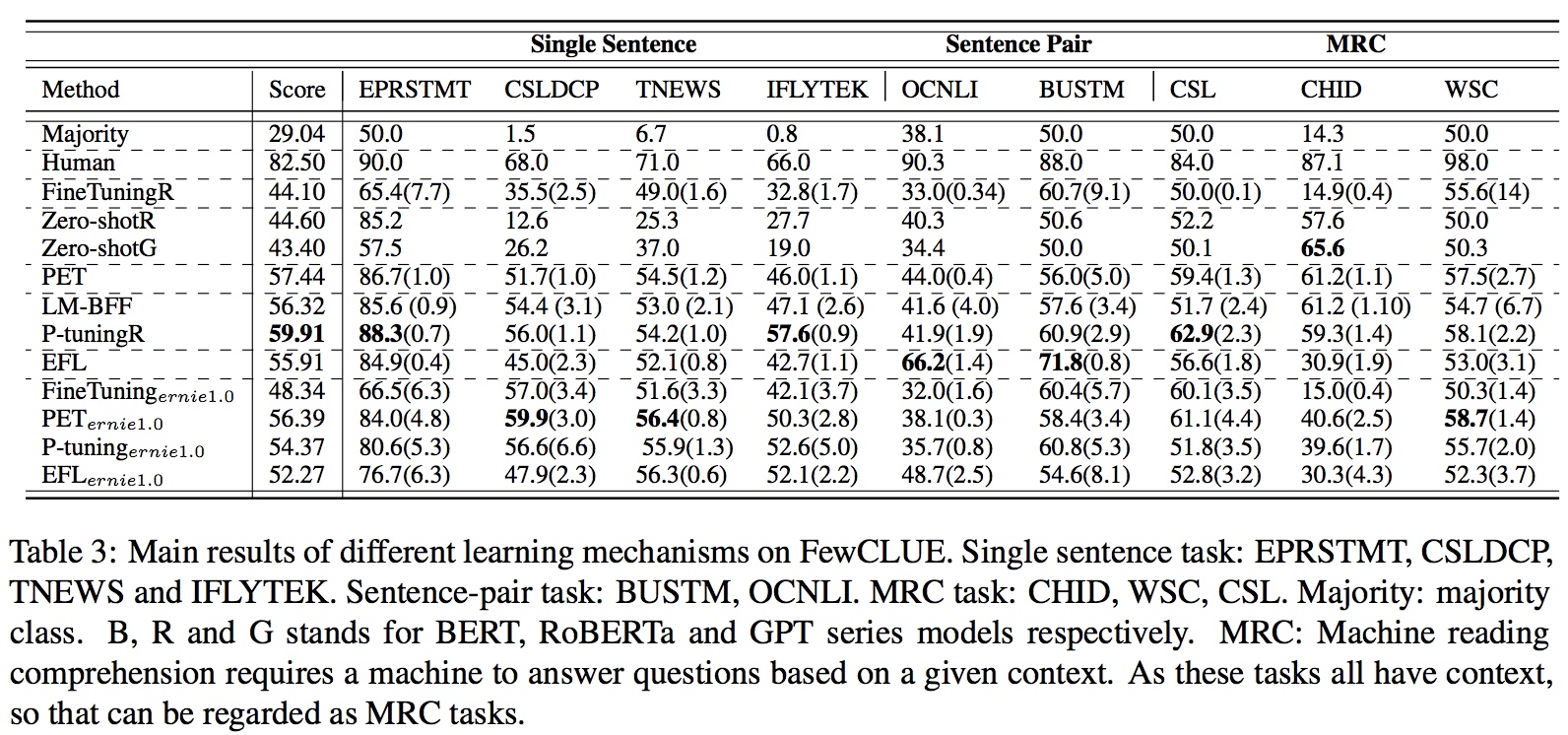
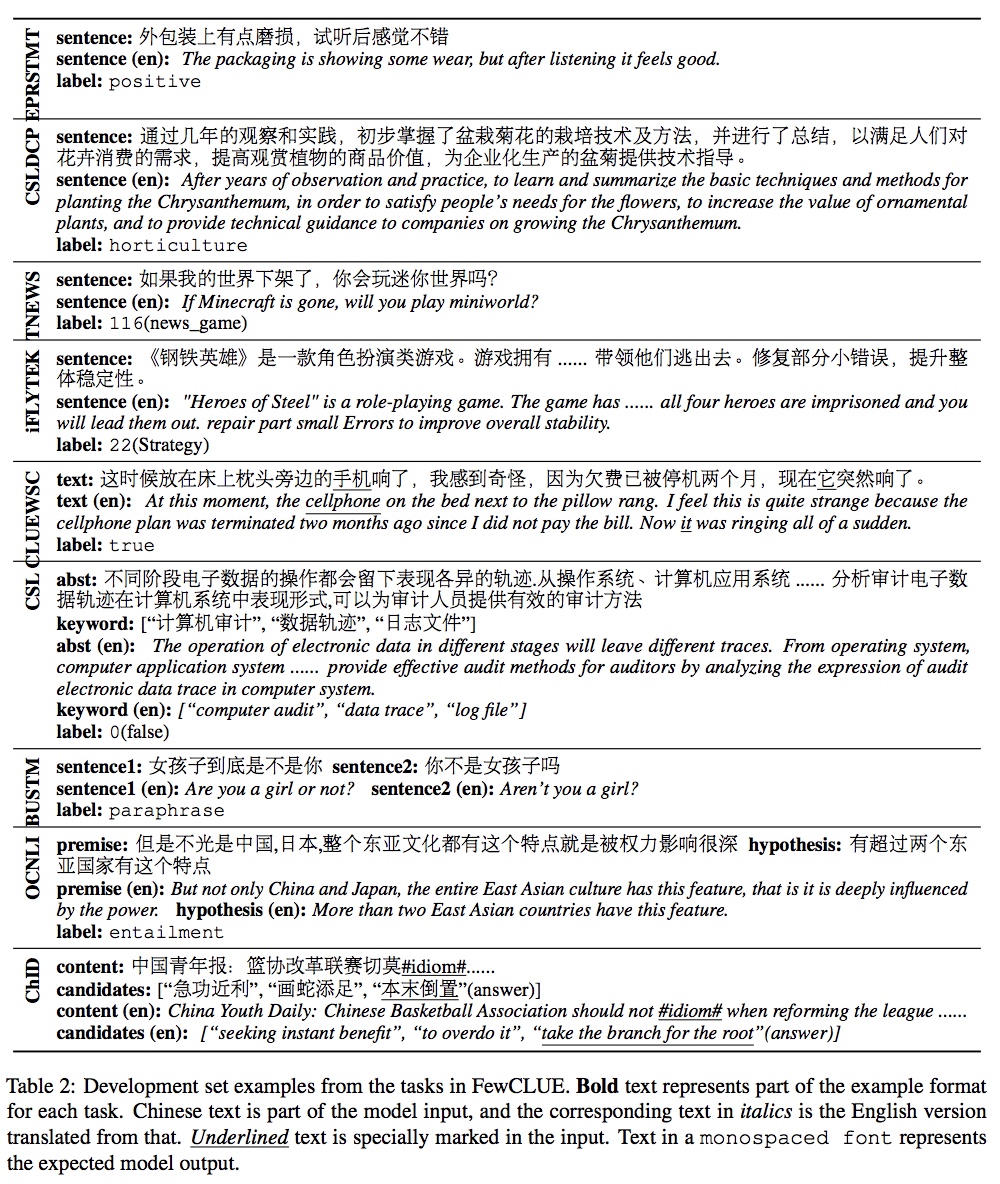
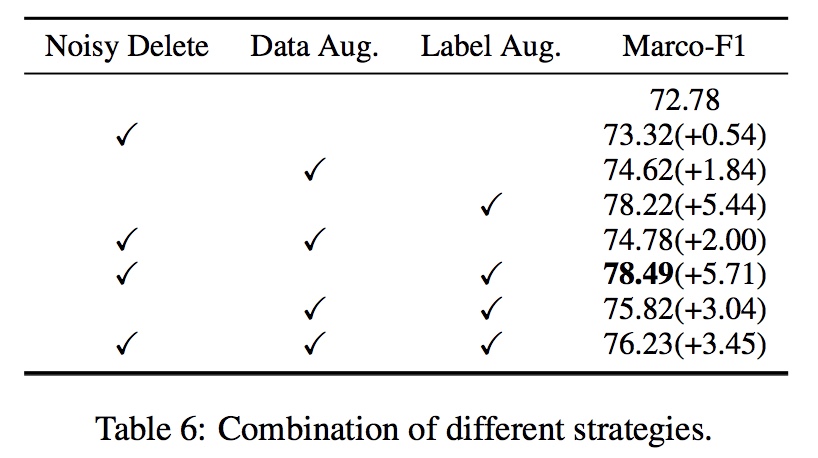
FewCLUE:小样本学习测评基准-中文版,为Prompt Learning定制的学习基准,9大任务,5份训练验证集,公开测试,NLPCC2021测评任务。
小样本学习(Few-shot Learning)解决这类在极少数据情况下的机器学习问题。结合预训练语言模型通用和强大的泛化能力基础上,探索小样本学习最佳模型和中文上的实践,是本课题的目标。结合少样本学习的特点和近期的发展趋势(Prompt Learning),精心设计了该任务。
下载地址:https://github.com/CLUEbenchmark/DataCLUE 中文文章 英文文章
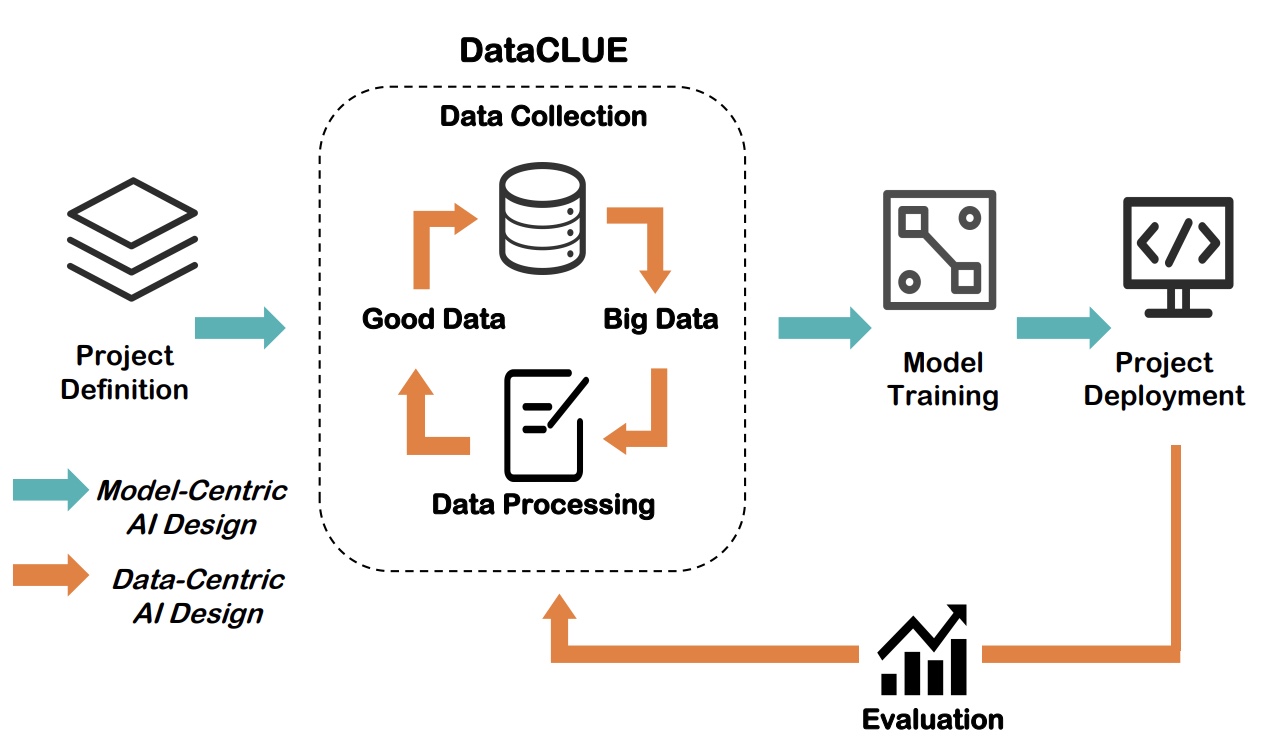
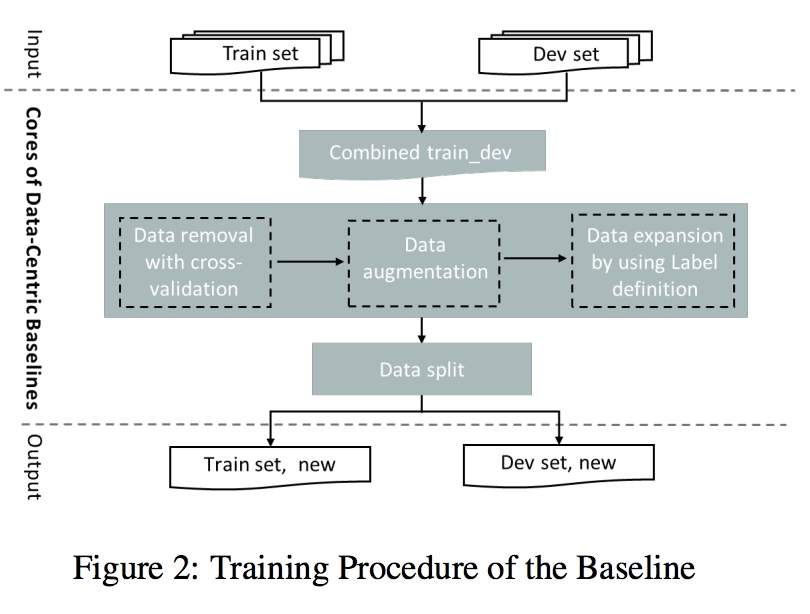
以数据为中心(Data-centric)的AI,是一种新型的AI探索方向。它的核心问题是如何通过系统化的改造你的数据(无论是输入或者标签)来提高最终效果。
传统的AI是以模型为中心(Model-centric)的,主要考虑的问题是如何通过改造或优化模型来提高最终效果,它通常建立在一个比较固定的数据集上。 最新的数据显示超过90%的论文都是以模型为中心的,通过模型创新或学习方法改进提高效果,即使不少改进影响可能效果并不是特别明显。有些人认为当前的人工智能领域, 无论是自然语言处理(如BERT) 或计算机视觉(ResNet), 已经存在很多成熟高效模型,并且模型可以很容易从开源网站如github获得;而与此同时,工业界实际落地 过程中可能有80%的时间用于 清洗数据、构建高质量数据集,或在迭代过程中获得更多数据,从而提升模型效果。正是看到了这种巨大的差别,在吴恩达等人的推动下这种 以数据为中心 (Data-centric)的AI进一步的系统化,并成为一个有具有巨大实用价值方法论。
DataCLUE是一个以数据为中心的AI测评。它基于CLUE benchmark,结合Data-centric的AI的典型特征,进一步将Data-centric的AI应用于 NLP领域,融入文本领域的特定并创造性丰富和发展了Data-centric的AI。在原始数据集外,它通过提供额外的高价值的数据和数据和模型分析报告(增值服务)的形式, 使得融入人类的AI迭代过程(Human-in-the-loop AI pipeline)变得更加高效,并能较大幅度的提升最终效果。

下载地址:https://github.com/CLUEbenchmark/ZeroCLUE 文章:https://arxiv.org/abs/2107.07498
ZeroCLUE:零样本学习测评基准-中文版,9大任务,5份训练验证集,公开测试,采用与小样本学习一致的任务进行评估;为Prompt Learning定制的学习基准。
零样本学习(Zero-shot Learning)是在通用的预训练模型基础上在模型没有调优情况下的机器学习问题。GPT系列模型展示了只依靠提示或示例即可以得到较好学习效果。结合预训练语言模型通用和强大的泛化能力基础上,探索零样本学习最佳模型和中文上的实践,是本课题的目标。
下载地址:https://github.com/CLUEbenchmark/KgCLUE 在线demo
KBQA(Knowledge Base Question Answering),是给定自然语言问题情况下通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。
KBQA利可以用图谱丰富的语义关联信息,能够深入理解用户问题并给出答案,近年来吸引了学术界和工业界的广泛关注。KBQA主要任务是将自然语言问题(NLQ)通过不同方法映射到结构化的查询,并在知识图谱中获取答案。
KgCLUE:中文KBQA测评基准,基于CLUE的积累和经验,并结合KBQA的特点和近期的发展趋势,精心设计了该测评,希望可以促进中文领域上KBQA领域更多的研究、应用和发展。


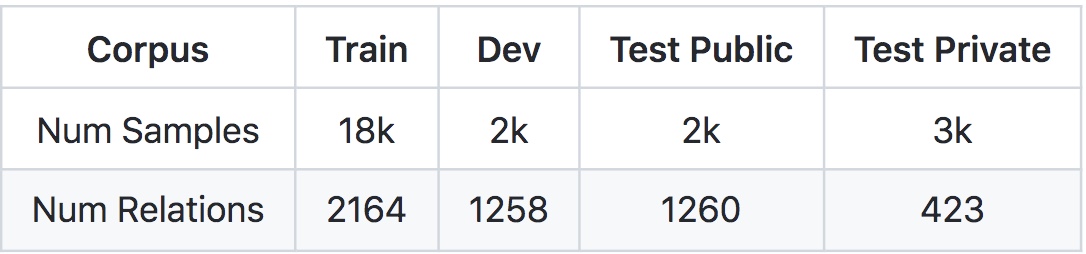

SimCLUE:大规模语义匹配数据集
提供一个大规模语义数据集;可用于语义理解、语义相似度、召回与排序等检索场景等。
作为通用语义数据集,用于训练中文领域基础语义模型。 可用于无监督对比学习、半监督学习、Prompt Learning等构建中文领域效果最好的预训练模型。整合了中文领域绝大多数可用的开源的语义相似度和自然语言推理的数据集,并重新做了数据拆分和整理。
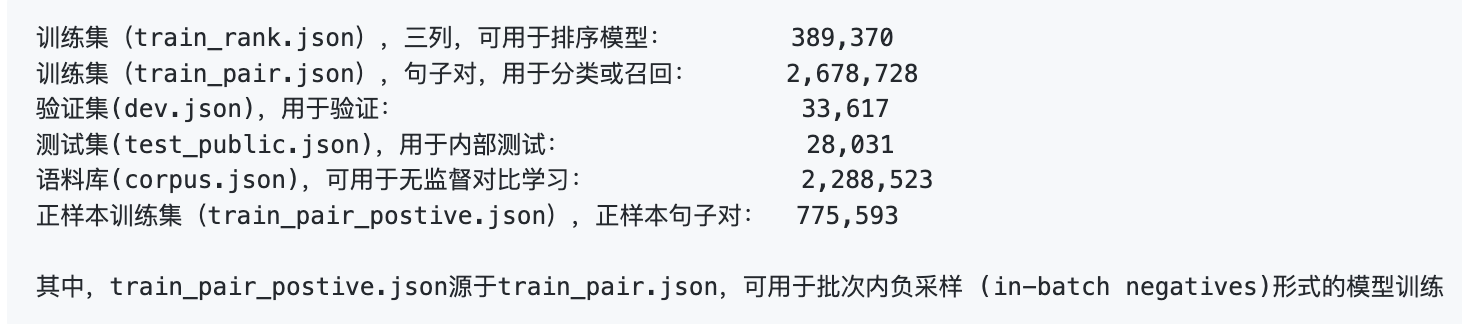

下载地址:https://github.com/CLUEbenchmark/QBQTC
QQ浏览器搜索相关性数据集(QQ Browser Query Title Corpus),是QQ浏览器搜索引擎目前针对大搜场景构建的一个融合了相关性、权威性、内容质量、 时效性等维度标注的学习排序(LTR)数据集,广泛应用在搜索引擎业务场景中。
相关性的含义:0,相关程度差;1,有一定相关性;2,非常相关。数字越大相关性越高。
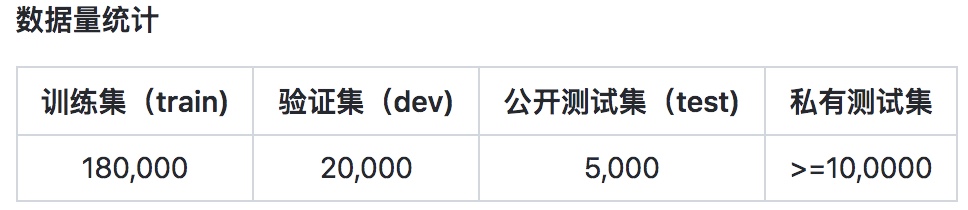

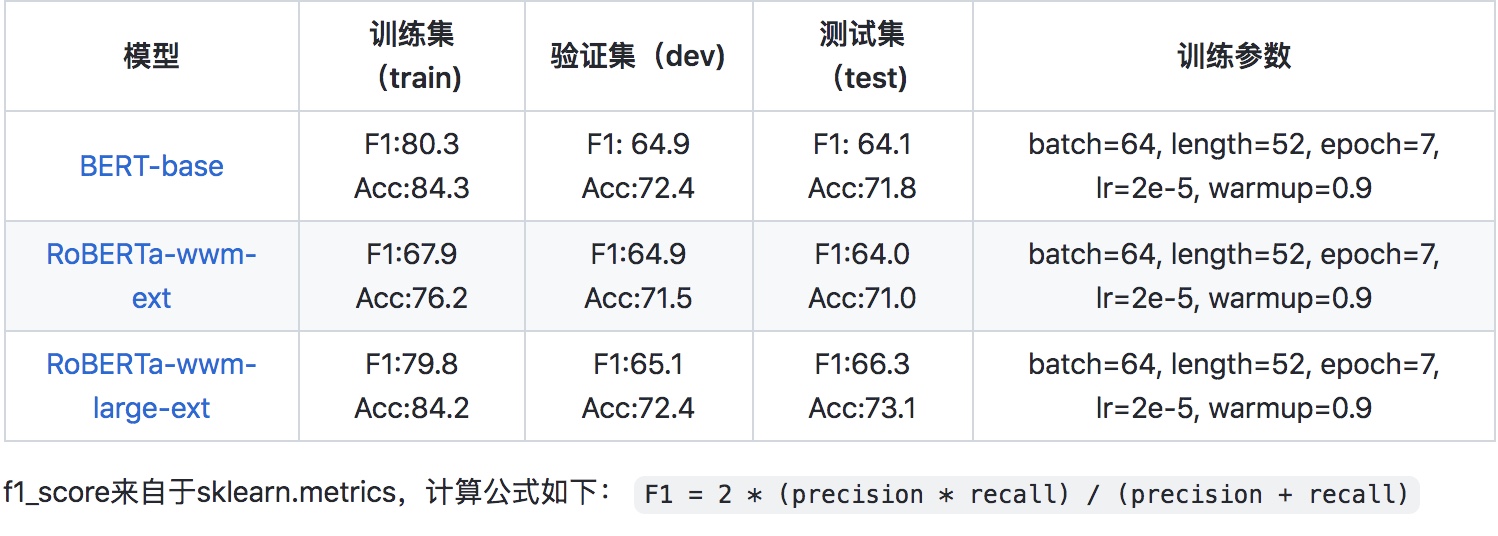
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
每一条数据有三个属性,从前往后分别是 句子1,句子2,句子相似度标签。其中label标签,1 表示sentence1和sentence2的含义类似,0表示两个句子的含义不同。
数据量:训练集(34334)验证集(4316)测试集(3861)
例子:
{"sentence1": "双十一花呗提额在哪", "sentence2": "里可以提花呗额度", "label": "0"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
每一条数据有三个属性,从前往后分别是 分类ID,分类名称,新闻字符串(仅含标题)。
数据量:训练集(266,000),验证集(57,000),测试集(57,000)
例子:
{"label": "102", "label_des": "news_entertainment", "sentence": "江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
该数据集共有1.7万多条关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:"打车":0,"地图导航":1,"免费WIFI":2,"租车":3,….,"女性":115,"经营":116,"收款":117,"其他":118(分别用0-118表示)。每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。
数据量:训练集(12,133),验证集(2,599),测试集(2,600)
例子:
{"label": "110", "label_des": "社区超市", "sentence": "朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。,朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
CMNLI数据由两部分组成:XNLI和MNLI。数据来自于fiction,telephone,travel,government,slate等,对原始MNLI数据和XNLI数据进行了中英文转化,保留原始训练集,合并XNLI中的dev和MNLI中的matched作为CMNLI的dev,合并XNLI中的test和MNLI中的mismatched作为CMNLI的test,并打乱顺序。该数据集可用于判断给定的两个句子之间属于蕴涵、中立、矛盾关系。每一条数据有三个属性,从前往后分别是 句子1,句子2,蕴含关系标签。其中label标签有三种:neutral,entailment,contradiction。
数据量:train(391,782),matched(12,426),mismatched(13,880)
例子:
{"sentence1": "新的权利已经足够好了", "sentence2": "每个人都很喜欢最新的福利", "gold_label": "neutral"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
威诺格拉德模式挑战赛是图灵测试的一个变种,旨在判定AI系统的常识推理能力。参与挑战的计算机程序需要回答一种特殊但简易的常识问题:代词消歧问题,即对给定的名词和代词判断是否指代一致。其中label标签,true表示指代一致,false表示指代不一致。
数据量:训练集(532),验证集(104),测试集(143)
例子:
{"target": {"span2_index": 28, "span1_index": 0, "span1_text": "马克", "span2_text": "他"}, "idx": 0, "label": "false", "text": "马克告诉皮特许多关于他自己的谎言,皮特也把这些谎言写进了他的书里。他应该多怀疑。"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
中文科技文献数据集包含中文核心论文摘要及其关键词。 用tf-idf生成伪造关键词与论文真实关键词混合,生成摘要-关键词对,关键词中包含伪造的则标签为0。每一条数据有四个属性,从前往后分别是 数据ID,论文摘要,关键词,真假标签。
数据量:训练集(532),验证集(104),测试集(143)
例子:
{"id": 1, "abst": "为解决传统均匀FFT波束形成算法引起的3维声呐成像分辨率降低的问题,该文提出分区域FFT波束形成算法.远场条件下,以保证成像分辨率为约束条件,以划分数量最少为目标,采用遗传算法作为优化手段将成像区域划分为多个区域.在每个区域内选取一个波束方向,获得每一个接收阵元收到该方向回波时的解调输出,以此为原始数据在该区域内进行传统均匀FFT波束形成.对FFT计算过程进行优化,降低新算法的计算量,使其满足3维成像声呐实时性的要求.仿真与实验结果表明,采用分区域FFT波束形成算法的成像分辨率较传统均匀FFT波束形成算法有显著提高,且满足实时性要求.", "keyword": ["水声学", "FFT", "波束形成", "3维成像声呐"], "label": "1"}
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
第二届“讯飞杯”中文机器阅读理解评测 (CMRC 2018)
数据量:训练集(短文数2,403,问题数10,142),试验集(短文数256,问题数1,002),开发集(短文数848,问题数3,219)
例子:
{ "version": "1.0", "data": [ { "title": "傻钱策略", "context_id": "TRIAL_0", "context_text": "工商协进会报告,12月消费者信心上升到78.1,明显高于11月的72。另据《华尔街日报》报道,2013年是1995年以来美国股市表现最好的一年。这一年里,投资美国股市的明智做法是追着“傻钱”跑。所谓的“傻钱”策略,其实就是买入并持有美国股票这样的普通组合。这个策略要比对冲基金和其它专业投资者使用的更为复杂的投资方法效果好得多。", "qas":[ { "query_id": "TRIAL_0_QUERY_0", "query_text": "什么是傻钱策略?", "answers": [ "所谓的“傻钱”策略,其实就是买入并持有美国股票这样的普通组合", "其实就是买入并持有美国股票这样的普通组合", "买入并持有美国股票这样的普通组合" ] }, { "query_id": "TRIAL_0_QUERY_1", "query_text": "12月的消费者信心指数是多少?", "answers": [ "78.1", "78.1", "78.1" ] }, { "query_id": "TRIAL_0_QUERY_2", "query_text": "消费者信心指数由什么机构发布?", "answers": [ "工商协进会", "工商协进会", "工商协进会" ] } ] } ] }
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
成语完形填空,文中多处成语被mask,候选项中包含了近义的成语。
数据量:训练集(84,709),验证集(3,218),测试集(3,231)
例子:
{ "content": [ # 文段0 "……在热火22年的历史中,他们已经100次让对手得分在80以下,他们在这100次中都取得了胜利,今天他们希望能#idiom000378#再进一步。", # 文段1 "在轻舟发展过程之中,是和业内众多企业那样走相似的发展模式,去#idiom000379#?还是迎难而上,另走一条与众不同之路。诚然,#idiom000380#远比随大流更辛苦,更磨难,更充满风险。但是有一条道理却是显而易见的:那就是水往低处流,随波逐流,永远都只会越走越低。只有创新,只有发展科技,才能强大自己。", # 文段2 "最近十年间,虚拟货币的发展可谓#idiom000381#。美国著名经济学家林顿·拉鲁什曾预言:到2050年,基于网络的虚拟货币将在某种程度上得到官方承认,成为能够流通的货币。现在看来,这一断言似乎还嫌过于保守……", # 文段3 "“平时很少能看到这么多老照片,这次图片展把新旧照片对比展示,令人印象深刻。”现场一位参观者对笔者表示,大多数生活在北京的人都能感受到这个城市#idiom000382#的变化,但很少有人能具体说出这些变化,这次的图片展按照区域发展划分,展示了丰富的信息,让人形象感受到了60年来北京的变化和发展。", # 文段4 "从今天大盘的走势看,市场的热点在反复的炒作之中,概念股的炒作#idiom000383#,权重股走势较为稳健,大盘今日早盘的震荡可以看作是多头关前的蓄势行为。对于后市,大盘今日蓄势震荡后,明日将会在权重和题材股的带领下亮剑冲关。再创反弹新高无悬念。", # 文段5 "……其中,更有某纸媒借尤小刚之口指出“根据广电总局的这项要求,2009年的荧屏将很难出现#idiom000384#的情况,很多已经制作好的非主旋律题材电视剧想在卫视的黄金时段播出,只能等到2010年了……"], "candidates": [ "百尺竿头", "随波逐流", "方兴未艾", "身体力行", "一日千里", "三十而立", "逆水行舟", "日新月异", "百花齐放", "沧海一粟" ] }
下载地址:https://github.com/CLUEbenchmark/CLUE 论文 一种实现思路
中文多选阅读理解数据集,包含对话和长文等混合类型数据集。
数据量:训练集(11,869),验证集(3,816),测试集(3,892)
例子:
[ [ "男:你今天晚上有时间吗?我们一起去看电影吧?", "女:你喜欢恐怖片和爱情片,但是我喜欢喜剧片,科幻片一般。所以……" ], [ { "question": "女的最喜欢哪种电影?", "choice": [ "恐怖片", "爱情片", "喜剧片", "科幻片" ], "answer": "喜剧片" } ], "25-35" ], [ [ "男:足球比赛是明天上午八点开始吧?", "女:因为天气不好,比赛改到后天下午三点了。" ], [ { "question": "根据对话,可以知道什么?", "choice": [ "今天天气不好", "比赛时间变了", "校长忘了时间" ], "answer": "比赛时间变了" } ], "31-109" ]
下载地址:https://github.com/CLUEbenchmark/CLUENER2020 文章 一种实现思路
本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS.
任务详情:CLUENER2020
训练集:10748 验证集:1343
标签类别:
数据分为10个标签类别,分别为:
地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
cluener下载链接:数据下载
例子:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {"name": {"叶老桂": [[9,
11]]}, "company": {"浙商银行": [[0, 3]]}}}
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}
标签定义与规则:
地址(address): **省**市**区**街**号,**路,**街道,**村等(如单独出现也标记),注意:地址需要标记完全,
标记到最细。
书名(book): 小说,杂志,习题集,教科书,教辅,地图册,食谱,书店里能买到的一类书籍,包含电子书。
公司(company): **公司,**集团,**银行(央行,中国人民银行除外,二者属于政府机构), 如:新东方,包含新华网/中国军网等。
游戏(game): 常见的游戏,注意有一些从小说,电视剧改编的游戏,要分析具体场景到底是不是游戏。
政府(goverment): 包括中央行政机关和地方行政机关两级。
中央行政机关有国务院、国务院组成部门(包括各部、委员会、中国人民银行和审计署)、国务院直属机构(如海关、税务、工商、环保总局等),军队等。
电影(movie): 电影,也包括拍的一些在电影院上映的纪录片,如果是根据书名改编成电影,要根据场景上下文着重区分下是电影名字还是书名。
姓名(name): 一般指人名,也包括小说里面的人物,宋江,武松,郭靖,小说里面的人物绰号:及时雨,花和尚,著名人物的别称,通过这个别称能对应到某个具体人物。
组织机构(organization): 篮球队,足球队,乐团,社团等,另外包含小说里面的帮派如:少林寺,丐帮,铁掌帮,武当,峨眉等。
职位(position): 古时候的职称:巡抚,知州,国师等。现代的总经理,记者,总裁,艺术家,收藏家等。
景点(scene): 常见旅游景点如:长沙公园,深圳动物园,海洋馆,植物园,黄河,长江等。
下载地址:https://github.com/CLUEbenchmark/OCNLI 论文 一种实现思路
OCNLI,即原生中文自然语言推理数据集,是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集。
OCNLI包含5万余训练数据,3千验证数据及3千测试数据。除测试数据外,我们将提供数据及标签。测试数据仅提供数据。OCNLI为中文语言理解基准测评(CLUE)的一部分。
10月22日之后,中文原版数据集OCNLI替代了CMNLI,使用bert_base作为初始化分数;可以重新跑OCNLI,然后再上传新的结果。
任务详情:OCNLI
训练集:50000+ 验证集:3000 测试集:3000
标签:
label0-label4的不同标注者打上的标签。使用投票机制确定最终的label标签,若未达成多数同意,则标签将为"-",(已经在我们的基准代码中处理了)
OCLNLI数据链接:OCLNLI数据
数据示例:
{
"level":"medium",
"sentence1":"身上裹一件工厂发的棉大衣,手插在袖筒里",
"sentence2":"身上至少一件衣服",
"label":"entailment",
"label0":"entailment","label1":"entailment", "label2":"entailment",
"label3":"entailment","label4":"entailment",
"genre":"lit",
"prem_id":"lit_635",
"id":0
}
字段说明:
level: 难易程度:easy, medium and hard
sentence1: 前提句子
sentence2: 假设句子
label: 投票表决最终标签,少数服从多数原则,无法确定的使用"-"标记(数据已处理好)。
label0 -- label4: 5个标注员打上的标签
genre: 主要是:gov, news, lit, tv, phone
prem_id: 前提id
id: 总id