SuperCLUE-Video
SuperCLUE-Industry: 中文原生工业大模型测评基准
随着大模型突飞猛进的发展,该项技术向各行业、各领域的渗透已成不可逆转的趋势。工业领域,作为国家重点发展、建设的,关乎国民经济命脉的重点行业,
大模型在其中的应用与布局已然取得了一些成绩,比如其可以用于工业领域的故障分析、辅助流程控制、代码生成等多个环节。
大模型虽适于工业应用,但多针对通用场景,不足以应对工业特有的专业性。工业数据包含术语、参数、流程及规范,通用模型难覆盖。
工业场景中文模型评估已起步但缺乏多轮开放式问题基准,导致开发者在模型优化和评估时无明确标准,难判其工业适宜性。
为深化和丰富工业模型评估体系,我们推出SuperCLUE-Industry(SC-Industry)。SC-Industry通过通过基础能力和应用能力两大方向、
六大维度对大模型进行效果评估,并加入了智能体Agent能力的测评。设计结合国际标准和中文特需,旨在推动工业大模型技术进步与创新。
文章地址:https://www.cluebenchmarks.com/superclue_industry.html
项目地址:https://github.com/CLUEbenchmark/SuperCLUE-Industry
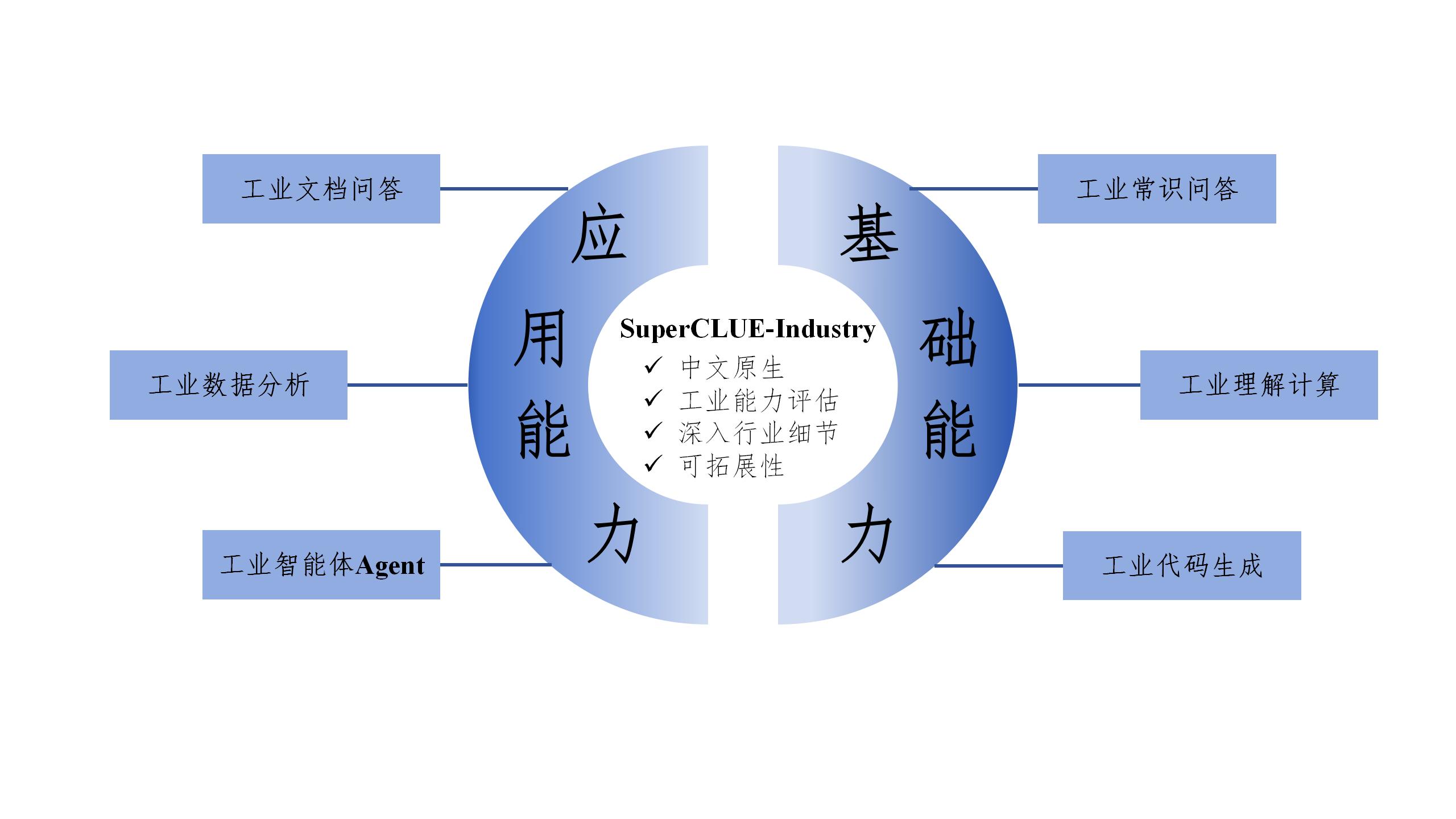
立足于为通用人工智能时代提供中文世界基础设施,文字输入或prompt提示词都是中文原生的;并充分考虑国内工业领域行业特点与应用场景,从国内各工业领域实际问题出发,致力于打造适合中国语义环境的工业测评指标。
在考察工业大模型对基础知识与技能的掌握与应用能力的同时,该测评体系深入行业具体应用实际,考察大模型在工业文档问答、工业数据分析以及充当工业智能体核心应用的综合能力,旨在全面地衡量工业大模型除知识库之外的具有实践意义的解决行业具体问题的应用能力。
SC-Industry旨在建立中文工业大模型测评的通用基准并逐步向各细分领域拓展。 如SuperCLUE目前已发布的汽车行业测评基准,此后会在诸如原材料、制造、加工等领域进一步完善指标体系。
参考SuperCLUE一贯的细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息。
中文prompt构建流程:1.参考现有prompt--->2.中文prompt撰写--->3.测试--->4.修改并确定中文prompt
参考国际标准和当前已有工作,针对每一个维度构建专用的测评集。
评估流程:1.获得<中文prompt>-->2.依据评估标准-->3.使用评分规则-->4.进行细粒度打分
结合超级模型,在定义的指标体系里明确每一个维度的评估标准。结合评估流程、评估标准、评分规则,将文本输入送入超级模型进行评估,并获得每一个维度的评估结果。
进行评估与人类一致性分析,并报告一致性表现。
从工业产品的设计、制造、技术规格,到操作维护、故障排除、以及安全标准等全阶段的信息交流和问题解答活动。
通过对工业领域特有指标的深入理解和准确计算来优化生产流程,提高产品质量,降低成本,以及保障工业安全。
评估模型在工业代码生成领域的能力。
基于二维表格类数据,如数组,大模型能分析数据并提供洞察。
基于工业类文档的问题,需要结合一个或多个文档内容来进行回答。问题的答案需要限定在文档范围内,如果返回没有相关信息,则说明文档中不存在指定内容。
考察模型能否在一定的工业环境中自主或半自主地执行任务,做出决策,并与其他系统进行交互来优化或辅助工业流程。
| 排名 | 模型名称 | 机构 | 总分 | 基础 能力 |
应用 能力 |
使用 方式 |
|---|---|---|---|---|---|---|
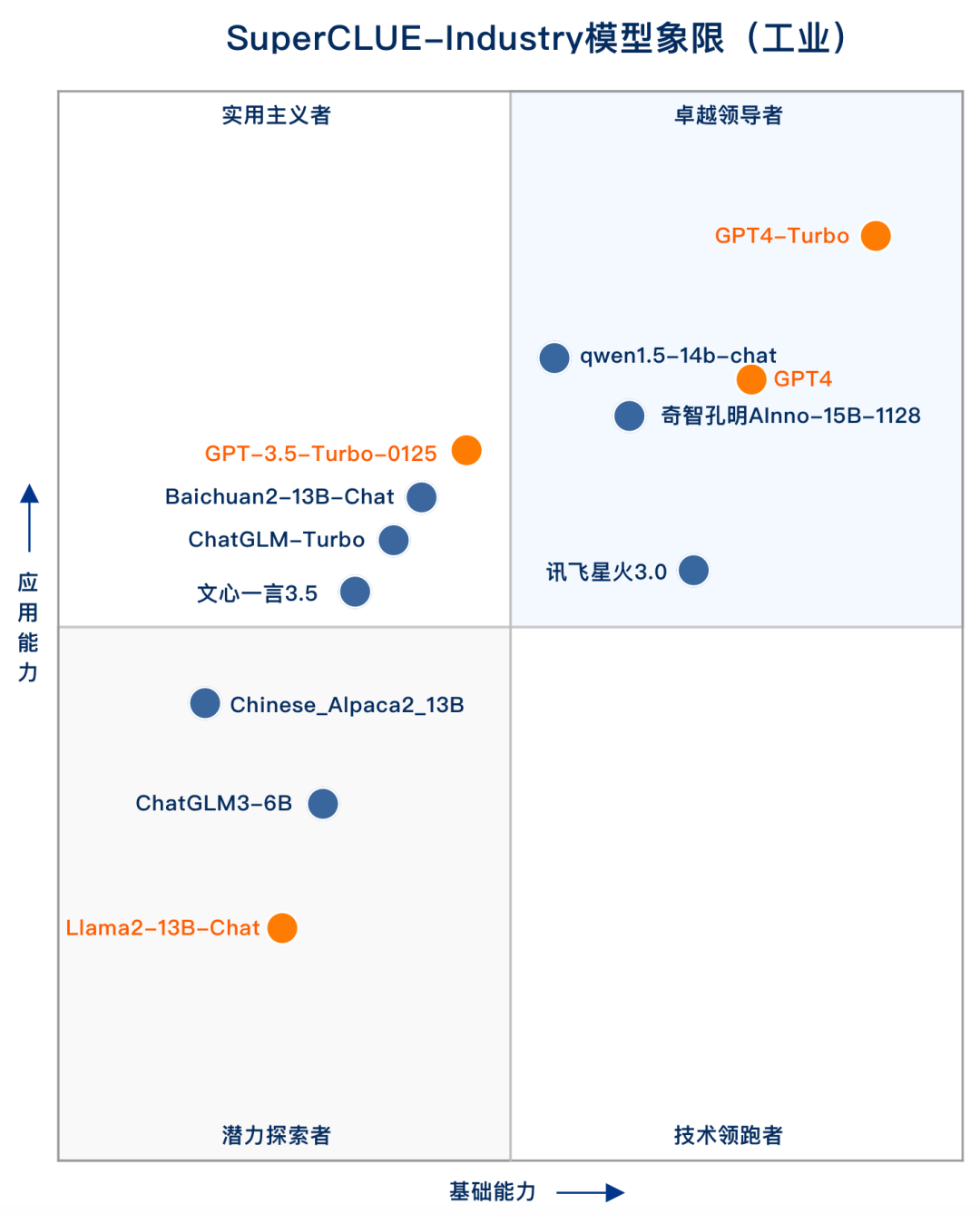
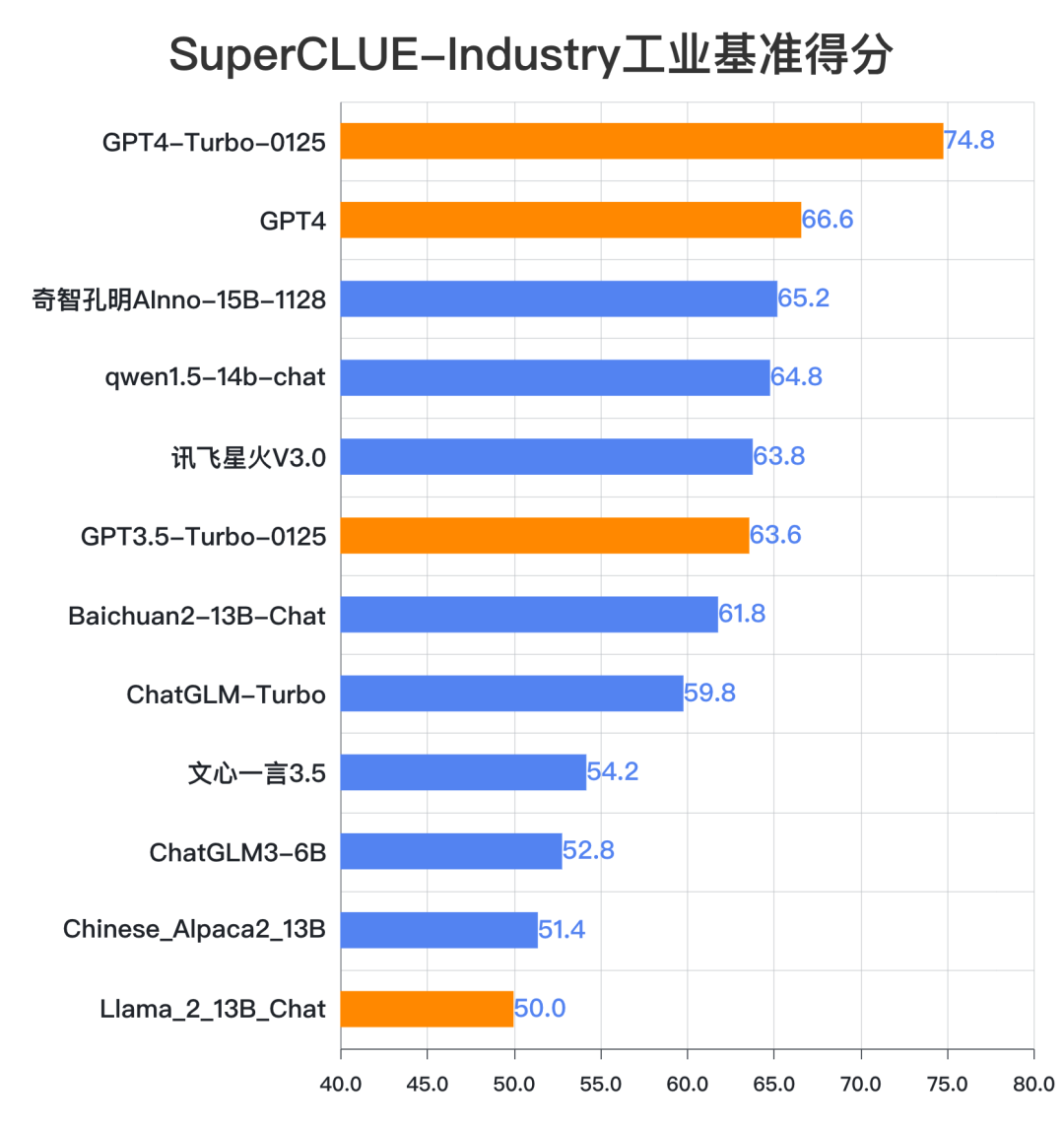
| - | GPT4-Turbo-0125 | OpenAI | 74.8 | 74.2 | 75.3 | API |
| - | GPT-4 | OpenAI | 66.6 | 65.5 | 67.6 | API |
| 🏅 | 奇智孔明AInno-15B-1128 | 创新奇智 | 65.2 | 63.3 | 67.2 | API |
| 🥈 | qwen1.5-14b-chat | 阿里巴巴 | 64.8 | 61.8 | 67.7 | API |
| 🥉 | 讯飞星火V3.0 | 科大讯飞 | 63.8 | 64.9 | 62.6 | API |
| - | GPT3.5-Turbo-0125 | OpenAI | 63.6 | 61.5 | 65.6 | API |
| 4 | Baichuan2-13B-Chat | 百川智能 | 61.8 | 60.1 | 63.3 | 模型 |
| 5 | ChatGLM-Turbo | 智谱AI | 59.8 | 56.7 | 63.0 | API |
| 6 | 文心一言3.5 | 百度 | 54.2 | 51.1 | 57.6 | API |
| 7 | ChatGLM3-6B | 智谱AI | 52.8 | 50.3 | 55.1 | 模型 |
| 8 | Chinese_Alpaca2_13B | yiming cui | 51.4 | 47.0 | 55.5 | 模型 |
| - | Llama_2_13B_Chat | Meta | 50.0 | 48.4 | 51.6 | 模型 |
| 排名 | 模型名称 | 机构 | 基础 能力 |
工业 常规问答 |
工业 理解计算 |
工业 代码生成 |
使用 方式 |
|---|---|---|---|---|---|---|---|
| - | GPT4-Turbo-0125 | OpenAI | 74.2 | 77.6 | 81.2 | 63.8 | API |
| - | GPT-4 | OpenAI | 65.5 | 67.6 | 73.4 | 55.6 | API |
| 🏅 | 讯飞星火V3.0 | 科大讯飞 | 64.9 | 68.6 | 74.2 | 52.0 | API |
| 🥈 | 奇智孔明AInno-15B-1128 | 创新奇智 | 63.3 | 69.2 | 67.1 | 53.5 | API |
| 🥉 | qwen1.5-14b-chat | 阿里巴巴 | 61.8 | 72.6 | 57.2 | 55.6 | API |
| - | GPT3.5-Turbo-0125 | OpenAI | 61.5 | 69.2 | 61.6 | 53.6 | API |
| 4 | Baichuan2-13B-Chat | 百川智能 | 60.1 | 73.8 | 49.6 | 57.0 | 模型 |
| 5 | ChatGLM-Turbo | 智谱AI | 56.7 | 72.2 | 51.0 | 46.8 | API |
| 6 | 文心一言3.5 | 百度 | 51.1 | 69.8 | 34.8 | 48.6 | API |
| 7 | ChatGLM3-6B | 智谱AI | 50.3 | 66.0 | 41.8 | 43.2 | 模型 |
| - | Llama_2_13B_Chat | Meta | 48.4 | 65.8 | 37.0 | 42.4 | 模型 |
| 8 | Chinese_Alpaca2_13B | yiming cui | 47.0 | 65.2 | 32.4 | 43.4 | 模型 |
| 排名 | 模型名称 | 机构 | 应用 能力 |
工业 数据分析 |
工业 文档问答 |
工业 智能体 |
|---|---|---|---|---|---|---|
| - | GPT4-Turbo-0125 | OpenAI | 75.3 | 73.8 | 81.0 | 71.0 |
| 🏅 | qwen1.5-14b-chat | 阿里巴巴 | 67.7 | 60.6 | 76.6 | 66.0 |
| - | GPT-4 | OpenAI | 67.6 | 65.0 | 73.6 | 64.2 |
| 🥈 | 奇智孔明AInno-15B-1128 | 创新奇智 | 67.2 | 61.4 | 76.1 | 64.0 |
| - | GPT3.5-Turbo-0125 | OpenAI | 65.6 | 60.2 | 76.0 | 60.6 |
| 🥉 | Baichuan2-13B-Chat | 百川智能 | 63.3 | 51.6 | 75.6 | 62.6 |
| 4 | ChatGLM-Turbo | 智谱AI | 63.0 | 53.8 | 74.6 | 60.6 |
| 5 | 讯飞星火V3.0 | 科大讯飞 | 62.6 | 61.6 | 71.0 | 55.2 |
| 6 | 文心一言3.5 | 百度 | 57.6 | 44.2 | 73.6 | 55.0 |
| 7 | Chinese_Alpaca2_13B | yiming cui | 55.5 | 43.0 | 73.0 | 50.4 |
| 8 | ChatGLM3-6B | 智谱AI | 55.1 | 39.4 | 72.4 | 53.4 |
| - | Llama_2_13B_Chat | Meta | 51.6 | 40.0 | 63.0 | 51.8 |
| 模型名称 | 机构 | 常规 问答 |
理解 计算 |
代码 生成 |
数据 分析 |
文档 问答 |
智能体 | 使用 方式 |
|---|---|---|---|---|---|---|---|---|
| GPT4-Turbo-0125 | OpenAI | 77.6 | 81.2 | 63.8 | 73.8 | 81.0 | 71.0 | API |
| GPT4 | OpenAI | 67.6 | 73.4 | 55.6 | 65.0 | 73.6 | 64.2 | API |
| 奇智孔明AInno-15B-1128 | 创新奇智 | 69.2 | 67.1 | 53.5 | 61.4 | 76.1 | 64.0 | API |
| qwen1.5-14b-chat | 阿里巴巴 | 72.6 | 57.2 | 55.6 | 60.6 | 76.6 | 66.0 | API |
| 讯飞星火V3.0 | 科大讯飞 | 68.6 | 74.2 | 52.0 | 61.6 | 71.0 | 55.2 | API |
| GPT3.5-Turbo-0125 | OpenAI | 69.2 | 61.6 | 53.6 | 60.2 | 76.0 | 60.6 | API |
| Baichuan2-13B-Chat | 百川智能 | 73.8 | 49.6 | 57.0 | 51.6 | 75.6 | 62.6 | 模型 |
| ChatGLM-Turbo | 智谱AI | 72.2 | 51.0 | 46.8 | 53.8 | 74.6 | 60.6 | API |
| 文心一言3.5 | 百度 | 69.8 | 34.8 | 48.6 | 44.2 | 73.6 | 55.0 | API |
| ChatGLM3-6B | 智谱AI | 66.0 | 41.8 | 43.2 | 39.4 | 72.4 | 53.4 | 模型 |
| Chinese_Alpaca2_13B | yiming cui | 65.2 | 32.4 | 43.4 | 43.0 | 73.0 | 50.4 | 模型 |
| Llama_2_13B_Chat | Meta | 65.8 | 37.0 | 42.4 | 40.0 | 63.0 | 51.8 | 模型 |
邮件标题:SuperCLUE-Industry工业测评申请,发送到contact@superclue.ai
请使用单位邮箱,邮件内容包括:单位信息、文生视频大模型简介、联系人和所属部门、联系方式


SuperCLUE中文大模型排行榜(2023年7月)
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| - | GPT-4 | OpenAI | 70.89 | 70.04 | 72.67 | 69.96 | 专有服务 |
| 🏅 | 文心一言(v2.2.0) | 百度 | 62.00 | 61.11 | 71.38 | 53.50 | 专有服务 |
| - | Claude-2 | Authropic | 60.94 | 62.01 | 61.18 | 59.63 | 专有服务 |
| - | gpt-3.5-turbo | OpenAI | 59.79 | 64.40 | 63.19 | 51.78 | 专有服务 |
| 🥈 | ChatGLM-130B | 清华大学&智谱AI | 59.35 | 53.78 | 71.39 | 52.89 | 专有服务 |
| 🥉 | 讯飞星火(v1.5) | 科大讯飞 | 58.02 | 63.32 | 65.72 | 45.03 | 专有服务 |
| - | Claude-instant-v1 | Authropic | 56.31 | 58.85 | 55.91 | 54.16 | 专有服务 |
| 4 | 360智脑(4.0) | 360 | 55.04 | 56.68 | 62.54 | 45.88 | 专有服务 |
| 5 | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 6 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 7 | MiniMax-abab5.5 | MiniMax | 53.06 | 53.61 | 62.79 | 42.77 | 专有服务 |
| 8 | 通义千问(v1.0.3) | 阿里巴巴 | 51.52 | 52.84 | 61.73 | 39.98 | 专有服务 |
| 9 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 10 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 11 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 12 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 13 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 14 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 15 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 16 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |
2023年7月SuperCLUE基础能力榜单
| 排名 | 模型 | 平均分 | 语义理解 | 闲聊 | 对话 | 角色扮演 | 知识与百科 | 生成与创作 | 逻辑与推理 | 代码 | 计算 | 安全 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 85.03 | 90.17 | 71.53 | 77.99 | 82.19 | 97.44 | 68.79 | 90.55 | 90.45 | 94.97 | 86.22 |
| - | gpt-4 | 70.04 | 82.91 | 46.77 | 66.39 | 63.46 | 92.65 | 66.67 | 60.33 | 85.45 | 61.48 | 73.02 |
| - | gpt-3.5-turbo | 64.40 | 87.18 | 45.16 | 65.57 | 60.58 | 85.29 | 72.36 | 42.98 | 72.73 | 38.52 | 72.22 |
| 🏅️ | 讯飞星火(v1.5) | 63.32 | 78.26 | 45.90 | 59.84 | 55.88 | 73.48 | 54.92 | 54.70 | 60.00 | 76.86 | 71.54 |
| - | Claude-2 | 62.01 | 83.49 | 49.59 | 57.14 | 52.88 | 78.68 | 68.07 | 53.72 | 66.06 | 44.26 | 65.60 |
| 🥈 | 文心一言(v2.2.0) | 61.11 | 81.90 | 46.34 | 56.67 | 59.80 | 86.76 | 47.73 | 36.52 | 65.79 | 52.63 | 70.63 |
| - | Claude-instant-v1 | 58.85 | 76.52 | 50.00 | 58.20 | 55.77 | 77.04 | 61.48 | 40.00 | 66.97 | 33.61 | 67.77 |
| 🥉 | 360智脑(4.0) | 56.68 | 76.92 | 52.46 | 58.33 | 54.08 | 76.80 | 61.54 | 37.29 | 53.64 | 29.57 | 67.92 |
| 4 | ChatGLM2-6B | 55.60 | 74.36 | 44.35 | 55.74 | 56.73 | 76.47 | 51.22 | 40.50 | 41.82 | 45.08 | 66.67 |
| 5 | internlm-chat-7b | 54.85 | 80.34 | 48.39 | 55.74 | 55.77 | 77.94 | 36.59 | 37.19 | 51.82 | 34.43 | 68.25 |
| 6 | ChatGLM-130B | 53.78 | 70.94 | 45.97 | 56.56 | 61.54 | 75.74 | 55.28 | 29.75 | 45.45 | 31.15 | 63.49 |
| 7 | MiniMax-abab5.5 | 53.61 | 79.49 | 45.97 | 59.84 | 60.58 | 85.29 | 47.97 | 29.75 | 30.00 | 31.97 | 61.11 |
| 8 | 通义千问 | 52.84 | 74.77 | 45.97 | 57.98 | 53.00 | 76.69 | 38.89 | 33.06 | 46.67 | 39.67 | 60.40 |
| 9 | Baichuan-13B-Chat | 50.46 | 64.10 | 41.94 | 50.00 | 52.88 | 75.00 | 57.72 | 27.27 | 40.91 | 31.15 | 60.32 |
| 10 | BELLE-13B | 48.71 | 68.38 | 46.77 | 51.64 | 53.85 | 64.71 | 25.20 | 32.23 | 48.18 | 31.97 | 63.49 |
| 11 | IDEA-姜子牙-13B-v1.1 | 47.55 | 70.09 | 49.19 | 48.36 | 48.08 | 58.82 | 32.52 | 34.71 | 21.82 | 45.08 | 63.49 |
| 12 | Phoenix-7B | 45.39 | 66.67 | 41.94 | 43.44 | 43.27 | 55.15 | 44.72 | 31.41 | 36.36 | 33.61 | 55.56 |
| 13 | MOSS-16B | 37.01 | 54.70 | 39.52 | 40.16 | 45.19 | 35.29 | 34.96 | 24.79 | 32.73 | 27.05 | 37.30 |
| 14 | Llama-2-13B-chat | 35.85 | 52.14 | 41.94 | 40.98 | 32.69 | 33.82 | 38.21 | 28.93 | 23.64 | 27.05 | 38.10 |
| 15 | Vicuna-13B | 34.61 | 49.57 | 33.06 | 32.79 | 37.50 | 25.74 | 30.89 | 27.27 | 40.91 | 35.25 | 35.71 |
| 16 | RWKV-7B-World-CHNtuned | 30.71 | 31.62 | 20.16 | 22.13 | 26.92 | 27.21 | 23.58 | 22.31 | 36.36 | 60.66 | 36.51 |
2023年7月SuperCLUE中文特性榜单
| 排名 | 模型 | 平均分 | 字形和拼音 | 字义理解 | 句法分析 | 文学 | 诗词 | 成语 | 歇后语 | 方言 | 对联 | 古文 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 82.29 | 96.01 | 83.15 | 62.71 | 91.47 | 90.79 | 92.38 | 83.78 | 69.21 | 70.00 | 83.40 |
| - | gpt-4 | 72.67 | 62.83 | 68.07 | 85.48 | 88.08 | 75.68 | 95.12 | 70.15 | 38.40 | 71.52 | 67.31 |
| 🏅️ | ChatGLM-130B | 71.39 | 48.67 | 68.07 | 75.00 | 83.44 | 84.68 | 95.94 | 67.16 | 45.60 | 70.86 | 72.12 |
| 🥈 | 文心一言(v2.2.0) | 71.38 | 59.34 | 70.34 | 73.33 | 86.58 | 82.88 | 95.12 | 60.31 | 37.60 | 71.03 | 73.79 |
| 🥉 | 讯飞星火(v1.5) | 65.72 | 47.32 | 68.38 | 77.42 | 72.03 | 69.09 | 89.43 | 59.85 | 35.77 | 71.23 | 63.46 |
| 4 | ChatGLM2-6B | 63.59 | 45.13 | 60.50 | 66.13 | 78.81 | 63.06 | 89.43 | 64.18 | 33.60 | 64.24 | 66.35 |
| - | gpt-3.5-turbo | 63.19 | 46.02 | 69.75 | 75.81 | 75.50 | 57.66 | 89.43 | 55.97 | 36.00 | 57.62 | 66.35 |
| 5 | MiniMax-abab5.5 | 62.79 | 46.90 | 57.98 | 63.71 | 75.50 | 71.17 | 86.99 | 60.45 | 41.60 | 58.94 | 62.50 |
| 6 | 360智脑(4.0) | 62.54 | 45.45 | 63.83 | 63.53 | 71.43 | 70.73 | 97.06 | 60.47 | 38.46 | 64.96 | 73.21 |
| 7 | 通义千问 | 61.73 | 41.59 | 60.87 | 60.66 | 73.65 | 67.89 | 88.24 | 51.91 | 40.68 | 68.97 | 57.89 |
| 8 | internlm-chat-7b | 61.35 | 41.59 | 58.82 | 62.10 | 76.16 | 68.47 | 86.18 | 61.94 | 32.80 | 57.62 | 65.38 |
| - | Claude-2 | 61.18 | 48.67 | 70.94 | 70.16 | 67.55 | 54.05 | 83.74 | 58.21 | 36.00 | 60.67 | 59.62 |
| - | Claude-instant-v1 | 55.91 | 43.36 | 62.16 | 72.13 | 62.91 | 50.91 | 84.87 | 47.73 | 31.20 | 56.38 | 45.19 |
| 9 | Baichuan-13B-Chat | 55.38 | 45.13 | 58.82 | 50.81 | 73.51 | 70.27 | 75.61 | 47.01 | 33.60 | 44.37 | 54.81 |
| 10 | BELLE-13B | 52.99 | 42.48 | 55.46 | 67.74 | 56.29 | 46.85 | 78.05 | 38.06 | 33.60 | 59.60 | 49.04 |
| 11 | IDEA-姜子牙-13B-v1.1 | 48.61 | 28.32 | 54.62 | 51.61 | 56.29 | 51.35 | 63.41 | 42.54 | 36.00 | 48.34 | 51.92 |
| 12 | Phoenix-7B | 44.62 | 30.09 | 51.26 | 43.55 | 51.66 | 45.95 | 65.85 | 35.07 | 32.00 | 45.03 | 44.23 |
| 13 | MOSS-16 | 38.01 | 32.74 | 43.70 | 36.29 | 40.40 | 32.43 | 60.98 | 32.09 | 31.20 | 31.13 | 40.38 |
| 14 | Llama-2-13B-chat | 37.37 | 31.86 | 40.34 | 49.19 | 37.75 | 33.33 | 43.90 | 32.09 | 32.00 | 33.77 | 40.38 |
| 15 | Vicuna-13B | 33.71 | 21.24 | 34.45 | 45.16 | 29.14 | 22.52 | 33.33 | 36.57 | 22.40 | 49.67 | 38.46 |
| 16 | RWKV-7B-World-CHNtuned | 28.13 | 25.66 | 26.05 | 25.00 | 29.80 | 26.13 | 45.53 | 17.16 | 20.00 | 36.42 | 27.88 |
2023年7月SuperCLUE开源榜单
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| 🏅️ | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 🥈 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 🥉 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 4 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 5 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 6 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 7 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 8 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 9 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 10 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |