FewCLUE:预训练模型的中文小样本学习
预训练语言模型,包括用于语言理解和文本生成的模型,通过海量文本语料上做语言模型的预训练的方式,极大提升了NLP领域上多种任务上的表现并扩展了NLP的应用。使用预训练语言模型结合成数千或上万的标注样本,在下游任务上做微调,通常可以取得在特定任务上较好的效果;但相对于机器需要的大量样本,人类可以通过极少数量的样本上的学习来学会特定的物体的识别或概念理解。小样本学习(Few-shot Learning )正是解决这类在极少数据情况下的机器学习问题。
结合预训练语言模型通用和强大的泛化能力基础上,探索小样本学习最佳模型和中文上的实践,是这次测评的目标。中文语言理解测评基准(CLUE)基于分类榜上的多个数据集,并结合少样本学习的特点和近期的发展趋势,精心设计了该任务,希望可以促进中文领域上少样本学习领域更多的研究和应用。
我们精选了多个有代表性的任务,将数据混合在一起形成一个综合的任务。选手提交的模型需要能同时预测每个任务对应的标签。
Github项目地址 https://github.com/CLUEbenchmark/FewCLUE
FewCLUE文章 https://arxiv.org/abs/2107.07498
NLPCC2021官网 http://tcci.ccf.org.cn/conference/2021/cfpt.php
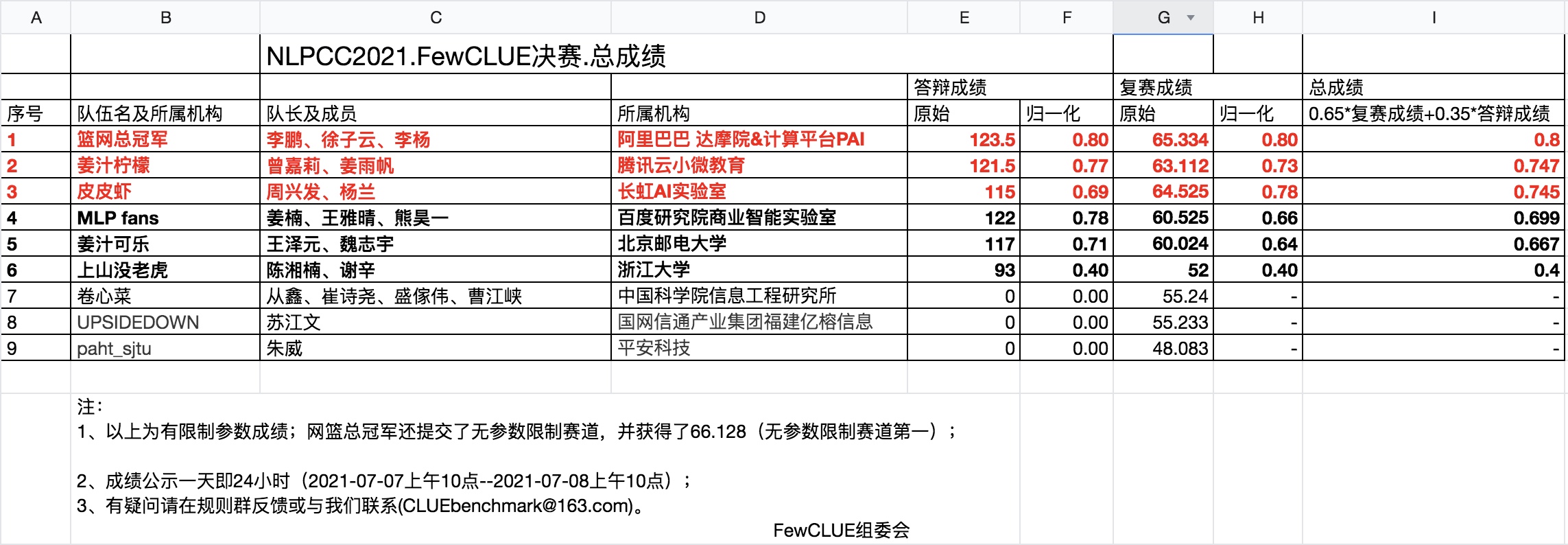
比赛证书:测评前三名队伍会获得NLPCC和CCF中国信息技术技术委员会认证的证书;优胜队伍有机会提交测评任务的论文(Task Report),并投稿到NLPCC会议(CCF推荐会议)
现金奖励:第一、二、三名分别奖励1万、5千、两千五(实在智能提供)
时间线:
4月10日比赛注册开始---->
4月30日发布训练集---->
5月30日比赛注册结束--->
6月25日发布测评结果---->
7月15日优胜队伍测评论文(task report)提交截止


查看注册信息